基于 CNN 的 AI 分类模型开发¶
本案例主要介绍如何快速利用 AIE Python SDK 创建机器学习建模流程。我们主要使用到 Python SDK的Machine Learning Proxy 模块(下文简称 AieMlProxy )。该模块涵盖了一系列用户与训练集群之间的交互接口,包括:鉴权、数据加载、训练任务提交、任务状态和日志查看、模型推理等。
导入 AIE Python SDK 包并初始化¶
In [ ]:
import aie
aie.Authenticate()
aie.Initialize()
创建工作目录¶
In [ ]:
PACKAGE_PATH = "cnn_clf_demo"
!ls -l
!mkdir {PACKAGE_PATH}
!mkdir {PACKAGE_PATH}/data
!touch {PACKAGE_PATH}/__init__.py
!ls -l {PACKAGE_PATH}
公开数据集¶
公开数据集包含 CV 和遥感领域常见的 benchmark ,通过 MlProxy 模块提供的 STAC 接口来查询和获取。
In [ ]:
# 导入AieMlProxy模块
from aie.client.mlproxy import MlProxy
In [ ]:
# 列出所有公开数据集
MlProxy.list_stac_datasets()
In [ ]:
# 通过dataset id获取数据集描述信息,以CIFAR-10数据集为例
stac_desc = MlProxy.get_stac_dataset("AIE_PUBLIC_DATA_CIFAR10_DATASET_V10_20220627")
print(stac_desc)
In [ ]:
# 获取数据集split
TRAIN_PATH = stac_desc.get('train_path')
VALID_PATH = stac_desc.get('valid_path')
print(VALID_PATH)
print(TRAIN_PATH)
私有数据集¶
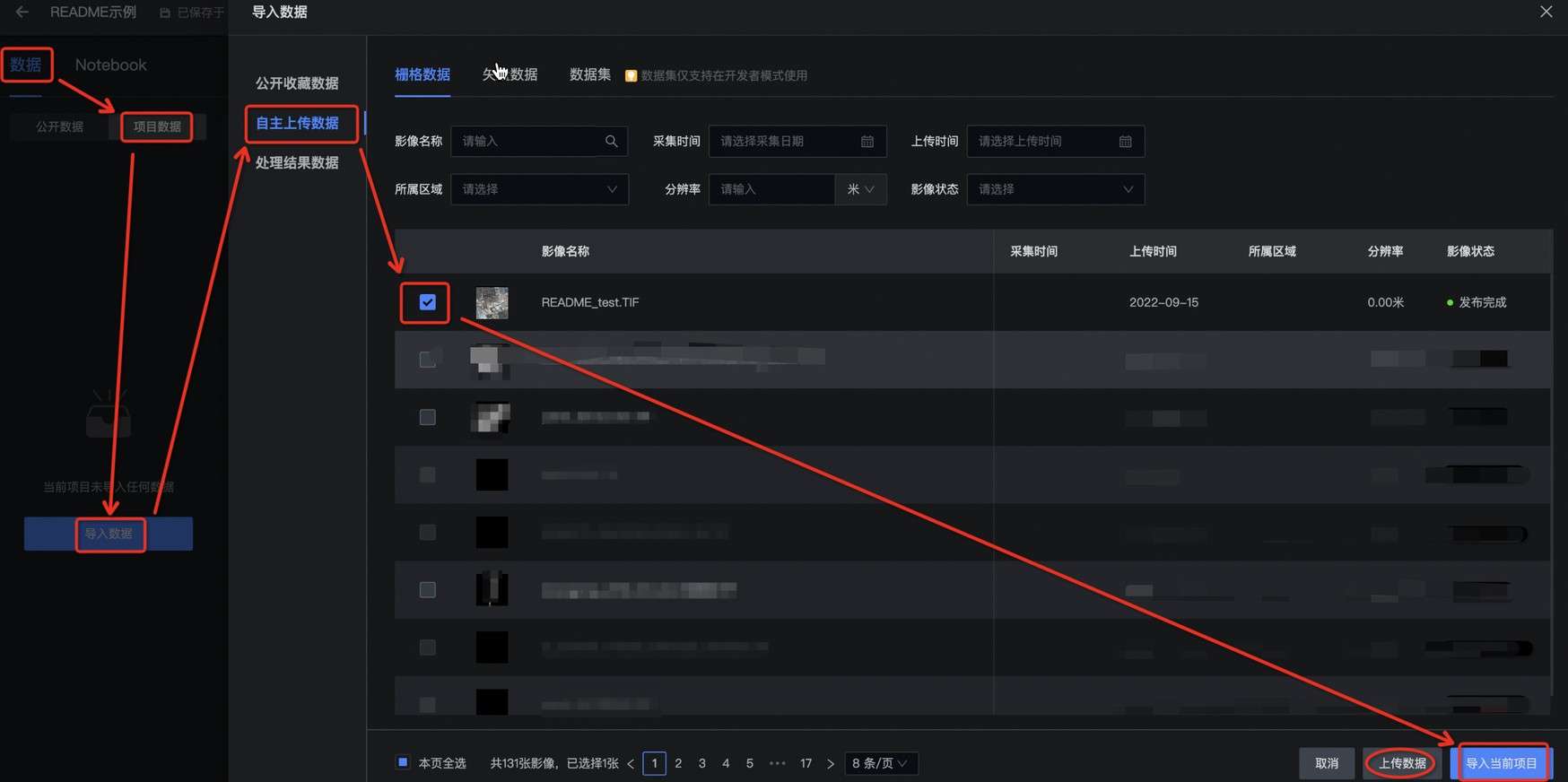
在本项目页面左侧,依次点击 数据 → 项目数据 → 导入数据 → 自主上传数据 以导入特定的单景影像到项目中。 私有数据集导入以后,默认会挂载到 /home/data 目录中(可使用终端命令行查看)
配置文件¶
In [ ]:
%%writefile {PACKAGE_PATH}/config.py
OSS_HOST = "oss-cn-hangzhou-internal.aliyuncs.com"
OSS_WORK_DIR = "pai/cnn_clf_demo"
OSS_CHECKPOINT_DIR = "pai/cnn_clf_demo/checkpoint"
OPEN_DATA_BUCKET = "aie-sample-data"
OPEN_DATA_ENDPOINT = "http://oss-cn-hangzhou-internal.aliyuncs.com"
# Ouput info
OUTPUT_MODEL_FILE_NAME = "cnnDemoModelBest.pth"
# Local tmp dir on PAI Cluster (to save dataset)
PAI_LOCAL_TMP_DIR = "./tmp/"
# Hyperparams
BATCH_SIZE = 256
NUM_LABELS = 10
NUM_EPOCHES = 1
STAC_TEST_PATH = ""
STAC_TRAIN_MAPPING_PATH = ""
STAC_CLASS_DICT_PATH = ""
In [ ]:
# 追加公开数据集split的路径到配置文件
!echo 'STAC_TRAIN_PATH = '\"{TRAIN_PATH}\" >> {PACKAGE_PATH}/config.py
!echo 'STAC_VALID_PATH = '\"{VALID_PATH}\" >> {PACKAGE_PATH}/config.py
下载数据集¶
本教程以公开数据集为例,展示如何加载远程数据集到 Notebook 环境
In [ ]:
# 下载数据集需要等待一段时间,具体视数据集大小而定
import os
from cnn_clf_demo import config
source_train_path = config.STAC_TRAIN_PATH.replace("oss://" + config.OPEN_DATA_BUCKET, "").strip("/")
target_train_path = os.path.join(PACKAGE_PATH, "data", source_train_path)
source_valid_path = config.STAC_VALID_PATH.replace("oss://" + config.OPEN_DATA_BUCKET, "").strip("/")
target_valid_path = os.path.join(PACKAGE_PATH, "data", source_valid_path)
data_abs_path = os.path.join(os.getcwd(), target_train_path)
os.makedirs(os.path.dirname(data_abs_path), exist_ok=True)
MlProxy.get_oss_object(source_train_path, target_train_path, oss_root_dir="./", oss_bucket_name=config.OPEN_DATA_BUCKET, oss_endpoint=config.OPEN_DATA_ENDPOINT)
MlProxy.get_oss_object(source_valid_path, target_valid_path, oss_root_dir="./", oss_bucket_name=config.OPEN_DATA_BUCKET, oss_endpoint=config.OPEN_DATA_ENDPOINT)
模型开发¶
datasets相关功能接口¶
In [ ]:
%%writefile {PACKAGE_PATH}/datasets.py
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
import torchvision.datasets as datasets
import torch
import tarfile
import oss2
import os
import json
def remove_invalid_file(data_dir):
for root, dirs, files in os.walk(data_dir, topdown=False):
for fname in files:
fpath = os.path.join(root, fname)
if fname.startswith("."):
os.remove(fpath)
print("** Remove invalid data finished .")
def load_tmp_cred_info(cred_file_path):
res = {}
with open(cred_file_path, "r") as f:
res = json.loads(f.readlines()[0])
return res
def download_oss_object(ak, akSec, security_token, host, bucket_name, source_object_path, target_object_path):
"""
Download oss file/gzip to local dir.
"""
auth = oss2.StsAuth(ak, akSec, security_token)
bucket = oss2.Bucket(auth, host, bucket_name)
bucket.get_object_to_file(source_object_path, target_object_path)
print("** Download finished !")
def upload_object_to_oss(ak, akSec, security_token, host, bucket_name, oss_filename, local_filename):
"""
Desc:
Put a local object to OSS.
Args:
oss_filename <string>: The oss filename. Example: pai/cnn_clf_demo/cnn_clf_demo.tar.gz
local_filename <string>: The local filename. Example: ./cnn_clf_demo.tar.gz
"""
auth = oss2.StsAuth(ak, akSec, security_token)
bucket = oss2.Bucket(auth, host, bucket_name)
bucket.put_object_from_file(oss_filename, local_filename)
print("** Upload finished !")
def untar(fname, dirs):
"""
解压tar.gz文件
:param fname: 压缩文件名
:param dirs: 解压后的存放路径
:return: bool
"""
try:
with tarfile.open(fname, "r:gz") as fp:
fp.extractall(path=dirs)
return True
except Exception as e:
print(e)
return False
def make_targz(output_filename, source_dir):
"""
一次性打包目录为tar.gz
:param output_filename: 压缩文件名
:param source_dir: 需要打包的目录
:return: bool
"""
try:
with tarfile.open(output_filename, "w:gz") as tar:
tar.add(source_dir, arcname=os.path.basename(source_dir))
return True
except Exception as e:
print(e)
return False
def get_data_loader(data_dir, transforms, batch_size, shuffle=True, num_workers=0):
# Get dataset obj
dataset = datasets.ImageFolder(
data_dir,
transforms
)
# Get torch dataLoader obj
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers
)
return data_loader
def get_transforms():
transformations = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
return transformations
模型网络定义¶
In [ ]:
%%writefile {PACKAGE_PATH}/model.py
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a CNN Net
class CnnDemoNet(nn.Module):
def __init__(self):
super(CnnDemoNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn3 = nn.BatchNorm2d(24)
self.conv4 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn3(self.conv3(output)))
output = F.relu(self.bn4(self.conv4(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
训练过程¶
In [ ]:
%%writefile {PACKAGE_PATH}/train.py
import os
import shutil
import torch.nn as nn
from torch.optim import Adam
from torch.autograd import Variable
import config
from datasets import *
from model import CnnDemoNet
import matplotlib.pyplot as plt
import numpy as np
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--inputs", type=str, default='Inputs dir')
parser.add_argument("--checkpointDir", type=str, default='Checkpoint dir')
args = parser.parse_args()
print("** InputsDir:", args.inputs)
print("** CheckpointDir:", args.checkpointDir)
tmp_cred_dict = load_tmp_cred_info(".tmp_info")
import torch
print("** torch version:", torch.__version__)
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("** The model will be running on", DEVICE, "device")
# create local tmp dir
os.makedirs(config.PAI_LOCAL_TMP_DIR, exist_ok=True)
def save_model(model, model_path):
torch.save(model.state_dict(), model_path)
## Test ACC
def test_acc(model, valid_loader, device):
model.eval()
acc = 0.0
total = 0.0
with torch.no_grad():
for data in valid_loader:
images,labels = data
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_,predicted = torch.max(outputs.data, 1)
total += labels.size(0)
acc += (predicted == labels).sum().item()
acc = (acc / total)
return (acc)
def data_process():
train_set_name = os.path.basename(config.STAC_TRAIN_PATH)
valid_set_name = os.path.basename(config.STAC_VALID_PATH)
# untar gzip packages
untar("./data/cifar-10/" + train_set_name, "./data")
untar("./data/cifar-10/" + valid_set_name, "./data")
# remove invalid data
remove_invalid_file("./data")
# get DataLoader
transformations = get_transforms()
train_loader = get_data_loader(os.path.join("./data", train_set_name.split(".")[0]), transformations, config.BATCH_SIZE, shuffle=True, num_workers=0)
valid_loader = get_data_loader(os.path.join("./data", valid_set_name.split(".")[0]), transformations, config.BATCH_SIZE, shuffle=False, num_workers=0)
return train_loader, valid_loader
# Training model
def train():
# Model instance
model = CnnDemoNet()
# Dataloaders
train_loader, valid_loader = data_process()
print("** Train len: ", len(train_loader))
print("** Valid len: ", len(valid_loader))
# Loss and Optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
# Training process
best_acc = 0.0
model.to(DEVICE)
for epoch in range(config.NUM_EPOCHES):
running_loss = 0.0
running_acc = 0.0
for i, (images,labels) in enumerate(train_loader, 0):
images = Variable(images.to(DEVICE))
labels = Variable(labels.to(DEVICE))
optimizer.zero_grad()
outputs = model(images)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 50 == 49:
print("[%d, %5d] loss: %.4f" % (epoch+1, i+1, running_loss/50))
running_loss = 0.0
# validation
acc = test_acc(model, valid_loader, DEVICE)
print("For epoch", epoch+1, "the acc on validation set is %.4f" % (acc))
if acc > best_acc:
# 暂存到临时文件夹
save_model(model, os.path.join(config.PAI_LOCAL_TMP_DIR, config.OUTPUT_MODEL_FILE_NAME))
best_acc = acc
# 将tmp目录中的 bestModel pth文件 传到OSS的checkpoint路径中 TMP_ACCESS_ID, TMP_ACCESS_SEC, config.OSS_HOST, TMP_BUCKET_NAME
upload_object_to_oss(tmp_cred_dict.get('ossStsAccessKeyId'),
tmp_cred_dict.get('ossStsAccessKeySecret'),
tmp_cred_dict.get('ossStsAccessSecurityToken'),
config.OSS_HOST,
tmp_cred_dict.get('ossBucketName'),
os.path.join(tmp_cred_dict.get('userWorkDir'), config.OSS_CHECKPOINT_DIR, config.OUTPUT_MODEL_FILE_NAME),
os.path.join(config.PAI_LOCAL_TMP_DIR, config.OUTPUT_MODEL_FILE_NAME))
# 清理临时文件夹
shutil.rmtree(config.PAI_LOCAL_TMP_DIR)
print("** Training process done .\n")
if __name__ == "__main__":
print("** Start training process.\n")
train()
代码打包上传¶
- 获取临时授权
- 代码打包
- 代码包上传到远端存储
In [ ]:
# 获取临时授权信息,并添加到代码包中
MlProxy.save_tmp_cred(PACKAGE_PATH)
# 代码打包,建议使用tar.gz格式
!cd {PACKAGE_PATH} && tar -zcvf {PACKAGE_PATH}.tar.gz --exclude=__pycache__ ./* .[!.]* && mv {PACKAGE_PATH}.tar.gz ../
In [ ]:
# 将代码包上传到云端
import os
from cnn_clf_demo import config
script_object_name = os.path.join(config.OSS_WORK_DIR, PACKAGE_PATH+".tar.gz")
local_filename = os.path.join(PACKAGE_PATH+".tar.gz")
print("** object_name:", script_object_name)
print("** local_filename:", local_filename)
MlProxy.put_oss_object(script_object_name, local_filename)
提交训练任务¶
- 组装训练参数 data
- 使用 MlProxy.commit_model_job() 函数提交任务到训练集群
- 提交任务后,返回任务 logview 链接,查看训练进度、打印输出和错误信息
In [ ]:
# 提交训练任务
import imp
import os
import cnn_clf_demo
from cnn_clf_demo import config
imp.reload(cnn_clf_demo.config)
# 装配任务参数
data = {'script': script_object_name, 'entryFile': 'train.py', 'checkpointDir': config.OSS_CHECKPOINT_DIR}
# 任务提交,返回带有jobId和jobLogview等信息的字典
ret = MlProxy.commit_model_job(data)
job_id = ret['jobId']
print(job_id)
查看任务状态¶
In [ ]:
# 获取任务状态
MlProxy.get_job_status(job_id)
查看任务日志¶
In [ ]:
print(ret['jobLogview'])
停止任务¶
In [ ]:
MlProxy.stop_job(job_id)
模型评估¶
评估主流程代码¶
In [ ]:
%%writefile {PACKAGE_PATH}/evaluation.py
import os
import shutil
from torch.autograd import Variable
import config
from datasets import *
from model import CnnDemoNet
import matplotlib.pyplot as plt
import numpy as np
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--inputs", type=str, default='Inputs dir')
parser.add_argument("--checkpointDir", type=str, default='Checkpoint dir')
args = parser.parse_args()
print("** InputsDir:", args.inputs)
print("** CheckpointDir:", args.checkpointDir)
import torch
print("** torch version:", torch.__version__)
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("** The model will be running on", DEVICE, "device")
# create local temp dir
os.makedirs(config.PAI_LOCAL_TMP_DIR, exist_ok=True)
# 由于在训练集群中需要与云端数据存储进行通信,所以需要获取临时授权信息
def load_model_file():
# get temp sts credentials
tmp_cred_dict = load_tmp_cred_info(".tmp_info")
model_object_key = os.path.join(tmp_cred_dict.get('userWorkDir'), config.OSS_CHECKPOINT_DIR, config.OUTPUT_MODEL_FILE_NAME)
local_model_path = os.path.join(config.PAI_LOCAL_TMP_DIR, config.OUTPUT_MODEL_FILE_NAME)
download_oss_object(tmp_cred_dict.get('ossStsAccessKeyId'),
tmp_cred_dict.get('ossStsAccessKeySecret'),
tmp_cred_dict.get('ossStsAccessSecurityToken'),
config.OSS_HOST,
tmp_cred_dict.get('ossBucketName'),
model_object_key,
local_model_path)
print("*** Load model file finished !")
return local_model_path
## Test ACC
def test_acc(model, valid_loader, device):
model.eval()
acc = 0.0
total = 0.0
model.to(device)
with torch.no_grad():
for data in valid_loader:
images,labels = data
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_,predicted = torch.max(outputs.data, 1)
total += labels.size(0)
acc += (predicted == labels).sum().item()
acc = (acc / total)
return (acc)
def imageshow(img):
img = img/2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
def testBatch(test_loader):
images,labels = next(iter(test_loader))
imageshow(torchvision.utils.make_grid(images))
print("")
def data_process():
valid_set_name = os.path.basename(config.STAC_VALID_PATH)
# untar gzip packages
untar("./data/cifar-10/" + valid_set_name, "./data")
# remove invalid data
remove_invalid_file("./data")
# get DataLoader
transformations = get_transforms()
valid_loader = get_data_loader(os.path.join("./data", valid_set_name.split(".")[0]), transformations, config.BATCH_SIZE, shuffle=False, num_workers=0)
return valid_loader
# Test model
def test(model_path):
# Model instance
model = CnnDemoNet()
# Dataloaders
valid_loader = data_process()
print("** Valid len: ", len(valid_loader))
# load model
model.load_state_dict(torch.load(model_path))
acc = test_acc(model, valid_loader, DEVICE)
print("--the evaluation ACC on valid_set is %.4f" % (acc))
# 清理临时文件夹
shutil.rmtree(config.PAI_LOCAL_TMP_DIR)
print("** Test process done .\n")
if __name__ == "__main__":
print("** Start Test process.\n")
model_path = load_model_file()
test(model_path)
评估代码打包和上传¶
- 临时授权文件加载和保存
- 代码打包
- 代码包上传到远端存储
In [ ]:
# 存储临时授权信息
MlProxy.save_tmp_cred(PACKAGE_PATH)
# 评估代码打包,建议使用tar.gz格式
!cd {PACKAGE_PATH} && tar -zcvf {PACKAGE_PATH}.tar.gz --exclude=__pycache__ --exclude=./data/cifar-10/train.tar.gz ./* .[!.]* && mv {PACKAGE_PATH}.tar.gz ../
In [ ]:
# 代码包上传到云端
import os
from cnn_clf_demo import config
script_object_name = os.path.join(config.OSS_WORK_DIR, PACKAGE_PATH+".tar.gz")
local_filename = os.path.join(PACKAGE_PATH+".tar.gz")
print("** object_name:", script_object_name)
print("** local_filename:", local_filename)
MlProxy.put_oss_object(script_object_name, local_filename)
评估任务提交¶
- 组装任务参数 data
- 使用 MlProxy.commit_model_job() 函数提交任务到集群
- 提交任务后,返回任务 logview 链接,查看评估进度、打印输出和错误信息
In [ ]:
# 提交评估任务
import imp
import os
import cnn_clf_demo
from cnn_clf_demo import config
imp.reload(cnn_clf_demo.config)
# 组装任务参数
data = {'script': script_object_name, 'entryFile': 'evaluation.py', 'checkpointDir': config.OSS_CHECKPOINT_DIR}
# 提交任务,返回jobId和jobLogview等信息的字典
ret = MlProxy.commit_model_job(data)
job_id = ret['jobId']
print(job_id)
查看评估任务状态¶
In [ ]:
MlProxy.get_job_status(job_id)
查看任务日志¶
In [ ]:
print(ret['jobLogview'])
停止评估任务¶
In [ ]:
MlProxy.stop_job(job_id)